PromSec(KDD24) Note
Abstract#
\paragraph{} 提供了PromSec框架,通过优化提示(prompts)来增强大型语言模型生成安全和功能性源代码的能力。该方法结合静态和动态分析,并提出了一种新的评估标准。
Introduction#
\paragraph{} 介绍研究背景,包括大型语言模型生成代码的潜力和相关挑战,尤其是安全性和功能性问题。阐述研究动机与目标。
Background#
How Secure are LLMs in Code Generation?#
\paragraph{} 回顾与安全代码生成、提示优化和大型语言模型相关的研究,分析现有方法的局限性。
PromSec Framework#
Code Fixes are One-to-Many#
PromSec 的团队表示,代码生成的问题是一对多的,对于同样的一个需求,可以通过多种不同路径来实现。
The Training and Operation Pipeline#
- \(p^*\) 是理想提示 optimal Prompt,\(p\) 是每个循环输入提示。
- \(c_0\) 是从用户输入的 Prompt 获得的原始生成代码,是 \(p_0\) 在第一步生成的生成结果。
- \(k(c)\) 是代码 \(c\) 中的 CWE 计数,作为代码生成安全性的评估指标。
- \(d(c, c_0)\) 表示 \(c_0\) 和 \(c\) 之间的功能差异性的指标。
- \(\alpha\) 和 \(\beta\) 是权重参数。
文章指出,这个 pipeline 存在一个挑战,prompt \(p\) 与 \(k(c)\) 和 \(d(c, c_0)\) 是不可微的,无法使用常规的梯度优化方法。文章通过 GAN (Generative Adversarial Network,生成对抗网络) 来解决这个问题,他们将他们的 GAN 模型称为 gGAN。
gGAN 通过更改其图形表示来纠正代码问题,然后将其转化为及时调整。在这里,输入驱动生成器产生满足特定标准的输出,而判别器则评估这些输出是否符合定义的要求。由于它对图形数据进行操作,因此被归类为基于 GNN 的 GAN。在这种情况下,可以使用基于图卷积网络 (GCN) 的 GAN [36] 等架构。
中间描述了 gGAN 的超参数以及相关的损失配置等内容,在此略过。
对比损失函数的设计旨在鼓励生成具有更少 CWE 的图形,并且在原始图形和生成的图形之间的嵌入中具有更大的相似性,从而保持代码功能。The design of the contrastive loss function aims to encourage the generation of graphs with fewer CWEs and greater similarity in embeddings between the original and generated graphs, thereby maintaining code functionality.
Discriminator Loss
Gradient Updates
Code-to-Graph Conversion。在建议的管道中,可以使用现成的解析器包(如 [8, 49])轻松地将代码转换为图形表示(例如 AST、CFG、DFG)。同样,将 AST 图转换为代码也是一项简单的任务,通过取消解析 AST 来实现。但是,将 CFG 转换为代码更为复杂。
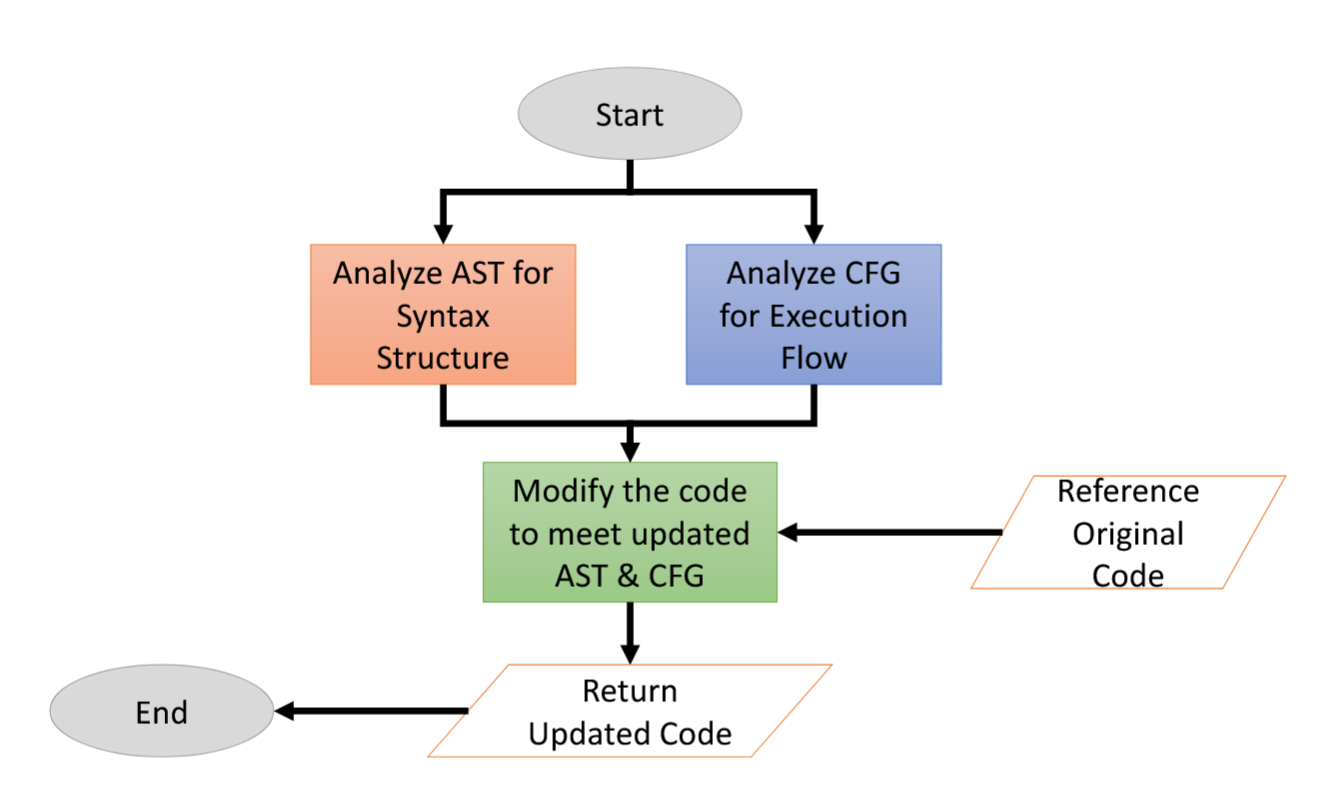
4.2. Security Assessment#
\paragraph{} 结合静态分析和动态分析工具评估生成代码的安全性,提出新的分析标准。
4.3. Functional Evaluation#
\paragraph{} 采用功能性测试评估生成代码的有效性,并与安全评估结果结合。
5. Experiments#
5.1. The Setup, Dataset, and Baselines#
第一个是从 [46] 获得的 Python 代码库集,包括来自 MITRE [58] 文档、CodeQL 文档 [29] 的源代码以及 [46] 作者的手工代码。
| BibTeX | |
|---|---|
我们向读者推荐附录 A.2 以了解有关此数据集的更多详细信息。第二个是从 [25, 71] 收集的 Java 提示数据集。对于安全性分析,我们选择了 Python 的 Bandit [18] 和 Java 的 SpotBugs [5],因为它们在检测质量和时间复杂度方面具有广泛的普及性和出色的性能。但是,任何其他静态安全工具都可用于此目的。
5.2. Baselines#
\paragraph{} 说明与PromSec比较的基线方法。
5.3. Metrics#
\paragraph{} 定义评估指标,包括安全性评分、功能性评分,以及整体性能评价。
6. Related Work#
This section briefly revisits prompt optimization for LLMs, especially for secure code generation, and GNNs for code analysis. Prompt Optimization for General LLM Tasks. Prompt engineering and optimization are crucial in maximizing the potential of LLMs. Works in this area vary by the assumed degree of LLM access and prompt treatment methods. Broadly, they can be divided into two main categories [38]. The first category considers soft prompts. These works consider a continuous prompt space represented as embeddings for the model [48, 39, 52]. This approach involves employing differentiable prompts for these soft embeddings. However, these studies presume familiarity with the latent embeddings of the LLM, leading to limitations in scalability. The second category involves hard prompts and adopts a discrete prompt treatment. This approach starts with an initial prompt and focuses on prompt engineering or optimization by generating a candidate set of feasible prompts and selecting the most suitable one. Examples along this line include the use of Monte-Carlo sampling by Zho et al. [74], gradient-based and beam search by Pryzant et al. [46], and genetic algorithm by Xu et al. [69]. However, these methods, while accomplishing some success, remain computationally intensive and lack assured convergence guarantees. Li et al. [36] offer another instance where reinforcement learning agents dynamically enhance provided prompts within textual LLM tasks, like translation and text summarization. While these endeavors advance prompt engineering, they underscore the persistent hurdle of crafting universally effective prompts. However, these efforts do not address prompt optimization for utilizing LLMs for source code generation. Furthermore, none of these studies delve into optimizing prompts for bolstering security measures.
Prompt Engineering and Optimization for Secure Code Generation. Recent research exhibits efforts for securing source code generation with LLMs. Along this line, Pearce et al. [44] use prompt engineering to guide LLMs with manually created prompt templates enriched with context from static security tools. However, this approach struggles with preserving the original functionality of the code and is constrained by the limitations of static security tools [8, 18]. Besides, incorporating more context from security reports does not necessarily improve performance. Charalambous et al. [8] use bounded model checking (BMC) to direct LLMs in generating memory-safe code. While successfully repairing buffer overflow and pointer dereference issues, this method is restricted to fixing memory safety issues detectable by BMCs. Other studies [29, 28] use reinforcement learning to enhance the security of code generated by LLMs, focusing on source code instead of prompts. Also, [23] employs trainable prefixes for influencing LLMs in either defense (security hardening) or offense (vulnerability creation). The optimization of a prefix requires access to the model’s parameters and hidden states. It thus restricts the applicability of this method to open-source models, excluding proprietary models like GPT, Bard, and Llama. Collectively, these studies underscore the need for more versatile and reliable methods in ensuring the security and functionality desiderata of code generated by LLMs.
GNNs for Source Code Analysis. Software engineering has significantly benefited from ML and deep learning advancements, with ASTs commonly used as input data [67]. GNNs have recently gained attention for semantic code analysis, marking a shift from traditional syntax-based methods. GNNs are effective in representing complex code structures and semantics, aiding in several tasks. In practical applications, GNNs have shown promise in software bug detection and correction. HOPPITY [16] uses GNNs for bug detection and fixing through graph transformations. Devgin [73] employs a heterogeneous GNN for vulnerability detection in source code by constructing a heterogeneous code graph. Code clone detection is another area where GNNs excel. They can uncover semantic similarities in clones that appear syntactically different. DeepSim [72] uses CFGs for clone detection, while [65, 37] combine various code graphs like ASTs, CFGs, and DFGs to improve clone detection accuracy. Additionally, [17] blends syntactic and semantic information for clone detection. This research body highlights the crucial role of GNNs and graph embeddings in source code analysis.
LLM任务的提示优化
提示工程和优化在最大化LLM的潜力方面至关重要。针对该领域的研究因对LLM访问权限的假设及提示处理方法的不同而有所变化。从广义上讲,这些方法可分为两大类 [38]。
第一类方法涉及软提示(Soft Prompts)。这类研究将提示视为模型的嵌入(Embeddings),并采用可微分的方式优化这些嵌入 [48, 39, 52]。然而,这些研究假设用户能够访问LLM的潜在嵌入空间,因此在可扩展性方面存在局限性。
第二类方法涉及硬提示(Hard Prompts),采用离散的提示处理方式。这种方法从初始提示开始,重点是通过提示工程或优化,生成一组可行的候选提示,并选择最合适的一个。例如,Zho等人 [74] 使用蒙特卡洛采样(Monte-Carlo Sampling),Pryzant等人 [46] 采用基于梯度的方法和束搜索(Beam Search),Xu等人 [69] 则应用遗传算法(Genetic Algorithm)。尽管这些方法在一定程度上取得了成功,但它们计算成本高,且缺乏收敛性保证。此外,Li等人 [36] 提出了一种基于强化学习的代理(Reinforcement Learning Agent),可在文本LLM任务(如翻译和文本摘要)中动态优化提示。然而,这些方法仍然面临如何设计通用有效的提示这一难题。
值得注意的是,现有研究并未针对LLM在源代码生成中的提示优化进行深入探讨,更未研究如何优化提示以增强安全性。
安全代码生成的提示工程与优化
近期研究开始关注利用LLM进行安全的源代码生成。Pearce等人 [44] 采用提示工程方法,通过手工设计的提示模板,引入静态安全工具的上下文来引导LLM。然而,该方法在保持代码原始功能方面存在困难,并且受限于静态安全工具的局限性 [8, 18]。此外,简单地引入更多安全报告的上下文信息,并不能保证性能的提升。
Charalambous等人 [8] 采用有界模型检查(BMC, Bounded Model Checking)来引导LLM生成内存安全的代码。尽管该方法成功修复了缓冲区溢出(Buffer Overflow)和指针解引用(Pointer Dereference)等问题,但其适用范围仅限于BMC能够检测到的内存安全问题。
此外,还有一些研究 [29, 28] 采用强化学习(Reinforcement Learning, RL)来增强LLM生成代码的安全性,但其优化对象是源代码而非提示。同时,研究 [23] 采用可训练前缀(Trainable Prefixes) 来影响LLM,使其生成更加安全(安全加固)或更具攻击性(漏洞创建)的代码。然而,该方法需要访问LLM的模型参数和隐藏状态,因此仅适用于开源模型,无法应用于专有模型(如GPT、Bard和Llama)。
总体而言,这些研究突显了在确保LLM生成代码的安全性和功能完整性方面,仍然需要更通用且可靠的方法。
基于GNN的源代码分析
近年来,软件工程受益于机器学习(ML)*和*深度学习(DL)*的进步,其中*抽象语法树(AST) 被广泛用作输入数据 [67]。随着研究的深入,图神经网络(GNN, Graph Neural Networks) 在语义代码分析方面得到了越来越多的关注,标志着从传统基于语法的方法向基于语义的方法的转变。
GNN能够有效地表示复杂的代码结构和语义,并在多个任务中表现良好:
-
软件漏洞检测与修复:HOPPITY [16] 通过图转换(Graph Transformations) 使用GNN进行漏洞检测和修复。
-
漏洞检测:Devgin [73] 采用异构GNN(Heterogeneous GNN),构造异构代码图(Heterogeneous Code Graph)来检测源代码中的漏洞。
-
代码克隆检测(Code Clone Detection)
:GNN在检测语法上不同但语义相似的代码克隆方面表现出色。例如:
- DeepSim [72] 采用控制流图(CFG) 进行克隆检测。
- 其他研究 [65, 37] 结合抽象语法树(AST)、控制流图(CFG) 和数据流图(DFG) 提高检测准确性。
- 研究 [17] 进一步融合语法信息和语义信息进行克隆检测。
这些研究充分表明,GNN及图嵌入(Graph Embeddings)在源代码分析中的关键作用,并为未来的研究提供了丰富的方向。
7. Results and Discussion#
7.1. Comparison with Baselines#
\paragraph{} 分析PromSec在安全性和功能性方面的表现,与基线方法进行对比。
7.2. Case Studies#
\paragraph{} 展示具体案例,说明PromSec在解决特定安全问题时的优势。
7.3. Limitations#
\paragraph{} 讨论PromSec方法的局限性及潜在改进方向。
8. Conclusion and Future Work#
\paragraph{} 总结研究贡献,并展望未来可能的研究方向。
References#
Reflection#
- PromSec 通过 GAN 进行代码重构与优化。但是 CWE 的个数只被当作一个指标。是否存在可能使得 CWE 也能作为帮助优化的指向性内容?
创建日期: February 21, 2025